
อีกไม่นานเราจะเผชิญหน้ากับพิลคาดาพร้อมกันจากนั้นไม่นานเราจะพบกับการเลือกตั้งทั่วไปปี 2019
นอกจากนี้เรามักจะเห็นผลการสำรวจที่มีระดับความสามารถในการเลือกตั้งของผู้สมัครผู้นำระดับภูมิภาค แต่อย่างที่เราเห็นบ่อยๆสถาบันการสำรวจแต่ละแห่งให้ผลลัพธ์ที่แตกต่าง
นี่เป็นส่วนหนึ่งของผลการสำรวจคู่ผู้สมัครชิงตำแหน่งผู้นำของ DKI Jakarta ที่จัดทำโดยสามสถาบันที่ผ่านมา มีเพียงวัตถุเดียวที่อยู่ระหว่างการศึกษา แต่ผลลัพธ์แตกต่างกันอย่างชัดเจน
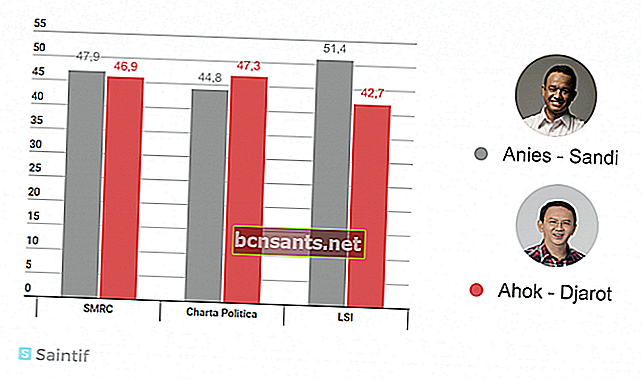
การวิจัยและการให้คำปรึกษา Saiful Mujani (SMRC)
Ahok-Djarot 46.9 เปอร์เซ็นต์และ Anis-Sandi 47.9 เปอร์เซ็นต์
วิธีการวิจัยใช้การสุ่มอย่างเป็นระบบแบบแบ่งชั้นโดยมีค่าความคลาดเคลื่อน 4.7 เปอร์เซ็นต์ จาก 800 คนสามารถสัมภาษณ์ผู้ตอบแบบสอบถามได้เพียง 446 คน
ชาร์ตาโปลิติกา
Ahok-Djarot 47.3 เปอร์เซ็นต์และ Anies-Sandi 44.8 เปอร์เซ็นต์
การสำรวจได้ดำเนินการกับผู้ตอบแบบสอบถาม 782 คนทั่วพื้นที่ DKI Jakarta และใช้วิธีการสุ่มแบบหลายขั้นตอนโดยมีค่าความคลาดเคลื่อนประมาณ 3.5 เปอร์เซ็นต์ที่ระดับความเชื่อมั่น 95 เปอร์เซ็นต์
วงกลมสำรวจโลก (LSI)
Ahok-Djarot 42.7 เปอร์เซ็นต์และ Anies-Sandi 51.4 เปอร์เซ็นต์
มีผู้ตอบแบบสอบถาม 440 คนโดยใช้วิธีการสุ่มตัวอย่างแบบหลายขั้นตอนและมีข้อผิดพลาดประมาณ 4.8 เปอร์เซ็นต์
แน่นอนว่านี่ไม่ใช่ผลการสำรวจครั้งเดียวจากสถาบันการสำรวจที่แตกต่างกัน เพื่อให้สอดคล้องกับการเลือกตั้งทั่วไปที่กำลังดำเนินอยู่สถาบันการสำรวจแต่ละแห่งจะยังคงแข่งขันกันเพื่อนำเสนอผลการสำรวจซึ่งแตกต่างกันไป
แล้วถ้าผลลัพธ์ต่างกันตรงไหนเชื่อถือได้?
ทำไมต้องสำรวจ
เรามีข้อ จำกัด ในการทำความเข้าใจข้อมูลที่สมบูรณ์เกี่ยวกับประชากรเสมอ ยิ่งมีจำนวนสมาชิกมากเท่าใดก็ยิ่งยากที่จะทราบค่าที่แน่นอนของข้อมูล
ดังนั้นเราจึงใช้วิธีการต่างๆและการสำรวจเป็นวิธีที่ง่ายที่สุด
การสำรวจเป็นวิธีการรวบรวมข้อมูลจากกลุ่มที่เป็นตัวแทนของประชากร วัตถุประสงค์ของการวิจัยเชิงสำรวจคือการกำหนดรายละเอียดทั่วไปของลักษณะของประชากร
แต่โปรดทราบว่าคำอธิบายของพารามิเตอร์ประชากรที่ได้จากการสำรวจโดยหลักการแล้วเป็นเพียงการประมาณหรือการประมาณเท่านั้น
ดังนั้นอย่าอ่านเพียงแค่ผลการสำรวจตามตัวเลขเท่านั้น แต่สังเกตลักษณะทางเทคนิคเพิ่มเติมที่มาพร้อมกับผลการสำรวจ
อ่านเพิ่มเติม: ความจริงเกี่ยวกับความยิ่งใหญ่ของนักวิทยาศาสตร์โลกขอบของข้อผิดพลาด
ขอบของข้อผิดพลาดอธิบายถึงระดับความไม่แน่นอนของผลการสำรวจและมีความสัมพันธ์อย่างใกล้ชิดกับจำนวนตัวอย่างการสำรวจต่อประชากรทั้งหมด
ยิ่งขอบของเปอร์เซ็นต์ความผิดพลาดมากเท่าใดตัวอย่างก็จะแสดงจำนวนประชากรได้มากขึ้นเท่านั้น ในทางกลับกันยิ่งขอบของข้อผิดพลาดน้อยลงตัวอย่างยิ่งใกล้เคียงกับการเป็นตัวแทนของประชากรจริง
ตัวอย่างเช่นผลการสำรวจระบุว่าข้อมูล A มีเปอร์เซ็นต์ 50% โดยมีส่วนต่างของข้อผิดพลาด 5% ซึ่งหมายความว่าข้อมูล A มีช่วงค่าระหว่าง 45% ถึง 55%
จากตัวอย่างของผลการสำรวจ SMRC ในตอนต้นไม่ถูกต้องที่จะบอกว่า Anis (47.9) เหนือกว่า Ahok (46.9) เพราะขอบของความผิดพลาดคือ 4.7 เปอร์เซ็นต์ นั่นหมายความว่าเปอร์เซ็นต์ของ Anis อยู่ในช่วง 43.2 - 52.6 เปอร์เซ็นต์ในขณะที่ Ahok อยู่ในช่วง 42.2 - 51.6
ในทำนองเดียวกันผลการสำรวจของ Charta Politica และ LSI ไม่ได้แสดงให้เห็นว่า Anis และ Ahok เหนือกว่าเนื่องจากค่าเปอร์เซ็นต์ + ขอบของข้อผิดพลาดระหว่างทั้งสองยังคงตัดกัน
พูดง่ายๆคือระยะขอบของข้อผิดพลาดคำนวณโดยใช้สมการ
[น้ำยาง] M = z \ times s / \ sqrt {n} [/ น้ำยาง]
โดยที่ z คือค่าคงที่ระดับความเชื่อมั่น s คือค่าเบี่ยงเบนมาตรฐานและ n คือขนาดตัวอย่าง

จากตัวอย่างการคำนวณง่ายๆนี้จะเห็นได้ว่ายิ่งค่าความคลาดเคลื่อนของตัวอย่างมีขนาดใหญ่เท่าใดก็ยิ่งมีขนาดเล็กลงเท่านั้น
วิธีการรวบรวมข้อมูล
มีวิธีการรวบรวมข้อมูลที่หลากหลายที่ใช้ในการสำรวจ สิ่งที่ใช้บ่อยที่สุด ได้แก่การสุ่มแบบแบ่งชั้นอย่างเป็นระบบและการสุ่มแบบหลายขั้นตอน

การสุ่มตัวอย่างอย่างเป็นระบบแบ่งชั้นจะจำแนกประชากรออกเป็นกลุ่มย่อยด้วยเกณฑ์เดียวกัน หลังจากนั้นจะสุ่มตัวอย่างตามขนาดของกลุ่มตัวอย่างจากนั้นดำเนินการอย่างเป็นระบบตามรูปแบบที่กำหนด
การสุ่มแบบหลายขั้นตอนทำการสุ่มตัวอย่างแบบแบ่งชั้น ตัวอย่างเช่นการสำรวจระยะแรกนำมาจากระดับเทศบาล จากนั้นในขั้นต่อไปได้นำตัวอย่างจากระดับตำบล ไปเรื่อย ๆ จนถึงระดับที่เล็กที่สุดและจำนวนกลุ่มตัวอย่าง
เทคนิคการสุ่มตัวอย่างที่แตกต่างกันเหล่านี้จะให้การวิเคราะห์ผลการวิจัยที่แตกต่างกันเนื่องจากลักษณะของวิธีการที่ใช้นั้นแตกต่างกันและมีความเอนเอียงเมื่อเปรียบเทียบกัน
สาเหตุอื่น ๆ ของข้อผิดพลาดในการสำรวจ
นอกเหนือจากเรื่องที่เกี่ยวข้องกับการสุ่มตัวอย่างและวิธีการรวบรวมข้อมูลแล้วยังมีสิ่งอื่น ๆ ที่อาจนำไปสู่ข้อผิดพลาดในผลการสำรวจ
อ่านเพิ่มเติม: คำอธิบายสาเหตุไฟฟ้าดับในชวาตะวันตกเมื่อวันอาทิตย์ที่ผ่านมาข้อผิดพลาดที่ไม่ใช่การสุ่มตัวอย่างเป็นข้อผิดพลาดที่เกิดขึ้นนอกเหนือจากการใช้ตัวอย่าง แต่เกิดขึ้นระหว่างขั้นตอนการดำเนินการแบบสำรวจ
หากในการสำรวจแบบไม่สุ่มตัวอย่างข้อผิดพลาดเกิดขึ้นมากแม้ว่าข้อผิดพลาดในการสุ่มตัวอย่าง / ข้อผิดพลาดระยะขอบจะมีขนาดเล็ก แต่ก็ยังไร้ประโยชน์ผลลัพธ์ที่ได้จะไม่ถูกต้อง
ข้อผิดพลาดที่ไม่ใช่การสุ่มตัวอย่างหลายประเภท ได้แก่
- ผู้ตอบไม่ตอบสนองเมื่อทำแบบสำรวจ
- ผู้ตอบให้การตอบกลับผิด
- ผู้ตอบแบบสอบถามที่ได้รับเลือกไม่ใช่บุคคลที่เหมาะสมกับวัตถุประสงค์ของการสำรวจ
- ผู้สัมภาษณ์ไม่ซื่อสัตย์ในการกรอกแบบสอบถาม
- ข้อผิดพลาดของมนุษย์ข้อผิดพลาดในการป้อนแบบสอบถาม
ผลการสำรวจความคิดเห็นของลูกค้าเป้าหมาย
ปัจจุบันสื่อมวลชนมีบทบาทสำคัญในการสร้างความคิดเห็นของประชาชน ดังนั้นหลายคนจึงพยายามใช้ประโยชน์จากมัน
หนึ่งในเครื่องมือที่ใช้คือผลการสำรวจเนื่องจากผลการสำรวจเป็นผลการวิจัยเพื่อให้สาธารณชนถือเป็นข้อมูลที่เป็นข้อเท็จจริงและเชื่อถือได้
สถาบันการสำรวจที่ไม่เป็นอิสระและมีส่วนได้เสียสามารถนำตัวอย่างมาพิจารณาเลือกกลุ่มตัวอย่างสำรวจเพื่อให้ได้ผลลัพธ์ที่เป็นบวก
และใช่ว่าปรากฏการณ์แบบนี้จะเกิดบ่อยขึ้นเมื่อเข้าสู่ช่วงการหาเสียงเลือกตั้งทั่วไป
สรุป
อย่างน้อยนี่คือสิ่งที่คุณต้องทำทุกครั้งที่คุณพบผลการสำรวจ
1. ต้องสงสัยในผลการสำรวจ
คุณไม่ควรเชื่อถือผลการสำรวจเนื่องจากพารามิเตอร์ประชากรที่ได้จากการสำรวจโดยหลักการแล้วเป็นเพียงการประมาณหรือการประมาณเท่านั้น
2. ศึกษาเพิ่มเติม
ผลการสำรวจจะมีค่าก็ต่อเมื่อเทคนิคนั้นชัดเจนวิธีการสุ่มตัวอย่างคืออะไรและขอบของข้อผิดพลาดคืออะไร
หากไม่มีตัวเลขนี้ก็มีความหมายเพียงเล็กน้อยและคุณควรสงสัยในผลการสำรวจ อาจเป็นไปได้ว่าการสุ่มตัวอย่างไม่สม่ำเสมอและระยะขอบของข้อผิดพลาดมีขนาดใหญ่เกินไปจึงไม่สามารถสรุปผลได้
ข้อมูลอ้างอิง
- การวิจัยเชิงสำรวจ - ยูเรก้าเอ็ดดูเคชั่น
- ควรเชื่อในผลการสำรวจ - Kompasiana
- ทำความเข้าใจเกี่ยวกับขอบของข้อผิดพลาดและวิธีการสุ่มตัวอย่างข้อมูล
- เชื่อผลสำรวจ - เยาวชนเชิงรุก
- เทคนิคการสุ่มตัวอย่างการวิจัย
- อินเทอร์เน็ตทำให้เราโง่มากยิ่งขึ้น